何思宇,邱玉宝,石利娟,丁磊,赵泉华,刘立京
1.辽宁工程技术大学,测绘与地理科学学院,辽宁阜新 123000
2.中国科学院空天信息创新研究院,数字地球重点实验室,北京 100094
3.西交利物浦大学,数学科学系,江苏苏州 215123
4.北京邮电大学,计算机学院,北京 100876
积雪是冰冻圈中快速变化的要素之一[1],相比于其他土地覆盖类型积雪具有高反射率特性,在区域辐射、平衡能量方面发挥重要的作用[2-3]。积雪分布非常广泛,全球平均每年积雪覆盖面积达4600万平方公里[4],在水循环具有重要的意义[5-6],可为人类提供重要的淡水补给[7]。青藏高原被称为“第三极”,是除极地之外最大雪冰覆盖的区域[8],据估计地面冰雪储量约为1.72106km²[9]。而喜马拉雅山位于青藏高原南颠边缘,是世界上海拔最高的山脉,也是青藏高原常年积雪面积最大的山脉[10]。喜马拉雅山东段积雪融水是雅鲁藏布江流域上游径流的主要来源,贡献量每年达78.8 mm,1990-2015年间东段地区冰雪融水大量增加[11],在1978-2006年间,雪深的年际变化非常显著[12]。因此,高质量、高分辨率的积雪数据是高原积雪和水资源变化研究的重要基础。
目前广泛应用的积雪数据产品主要有MODIS积雪产品[13]、IMS积雪产品[14]、AVHRR积雪产品[15]、ESA GlobSnow积雪产品[16]等,这些中低分辨率遥感数据对于理解全球或区域尺度的积雪变化提供了重要的参考。喜马拉雅山地势复杂、气候特殊,地表类型不单一,现有的中低分辨率积雪气候数据集在分析喜马拉雅山局部地区积雪精细变化上存在细节不足,Landsat 8拥有9年的数据积累,在冬季山区的观测量也较其他高分辨率光学遥感数据多,空间分辨率为30 m,是当前开展该地区积雪较好的数据源,提供更高精度的空间观测。
数据集以Landsat 8为基础,采用支持向量机方法开展积雪制图工作,并结合冰湖及地表水体数据,制备2013-2020年30 m分辨率Landsat晴空条件积雪数据集。
喜马拉雅山常年被冰雪覆盖,是中国与印度、尼泊尔、不丹、巴基斯坦等国的天然国界。西起克什米尔南迦-帕尔巴特峰,东至雅鲁藏布江的南迦巴瓦峰,全长2450 km,宽度达200-350 km[17]。在Randolph Glacier Inventory 6.0(RGI 6.0)将该喜马拉雅山地区分为3个子区域,即喜马拉雅山脉西段、中段和东段[18]。研究区位于喜马拉雅山脉中段和东段(26°-31°N,77°-95°E),如图1所示高亮显示区域,中段包括世界上海拔最高的珠穆朗玛峰(8844 m),也是高大山体分布最密集的区域,东段包括洛子峰(8516 m)、绰莫拉日峰活动频繁的冰川,相比于喜马拉雅山中段和西段年均退缩率最大[19]。
1.2.1 Landsat 8数据
使用来自美国地质调查局(USGS)Landsat 8系列的遥感数据,选用其一级产品共11个波段,空间分辨率为30 m。选取2013年3月至2020年12月云量少于10%的影像数据共607景。

图1 研究区概况图(底图为2020年全球10米土地覆盖[20])Figure 1 Overview of the study areas (The base map indicates the global 10-meter land cover in 2020[20])
所有数据根据年份和月份进行汇总(表1),由于本文选取云量少于10%的Landsat 8 OLI影像,在春夏季数据量较少,考虑是由于高海拔地区作为冷热源使高原总云量和云底高度的季节变化,空气在夏季辐合而冬季辐散[21],导致夏季云量明显多于冬季,所以获取到的数据主要分布在当年10月至次年4月。
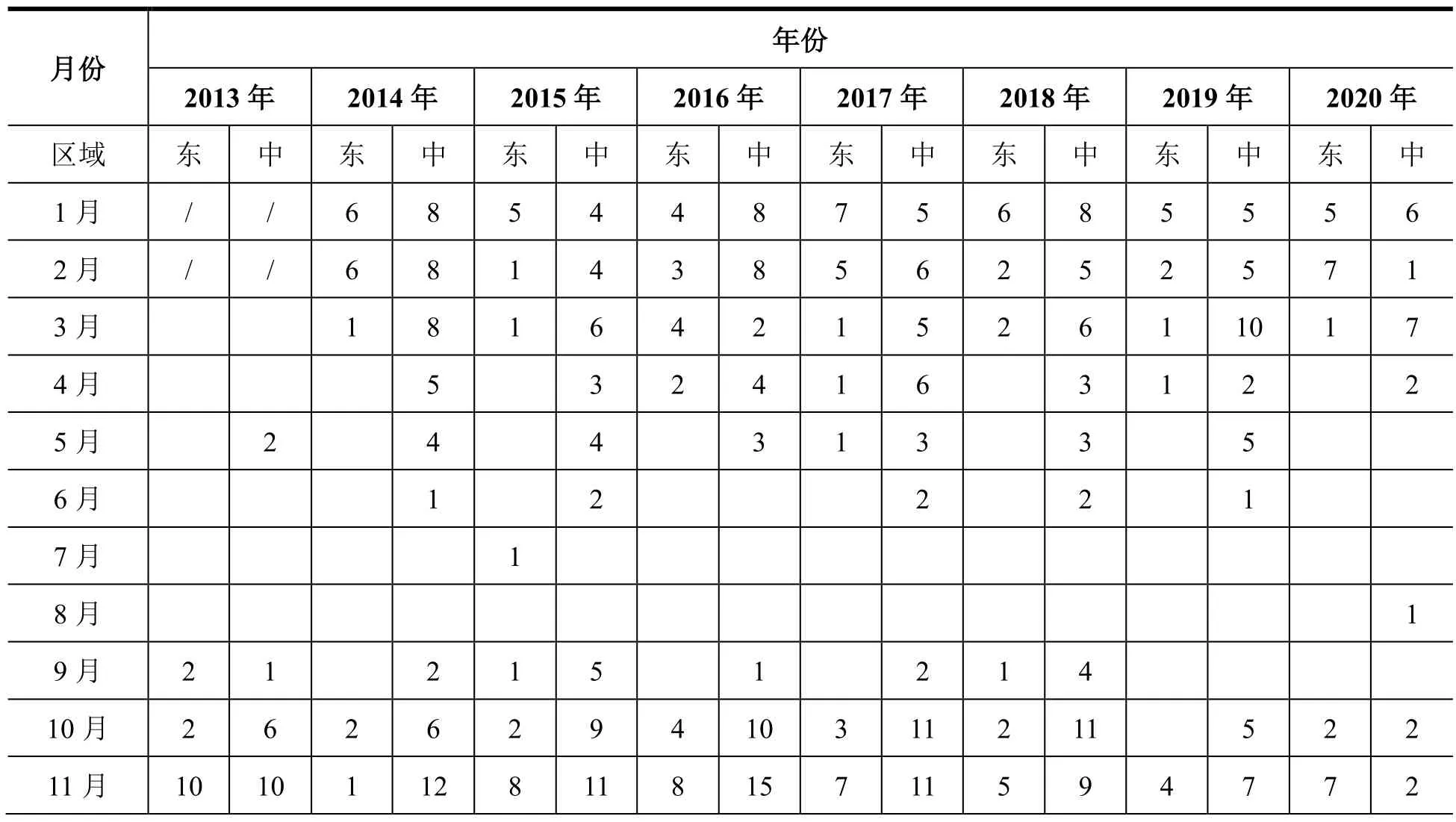
表1 2013-2020年喜马拉雅山中段和东段Landsat 8数据Table 1 Landsat 8 data of the middle and eastern Himalayas from 2013 to 2020

注: Landsat 8卫星于2013年2月11日发射,“/”表示数据不存在。
1.2.2 冰湖矢量数据
共选用两套冰湖数据,其中包含选用从Landsat导出的1990年和2018年亚洲高山冰川数据[22],该数据集综合了喜马拉雅地区冰川清单数据和1990年、2018年668景Landsat TM、ETM+和OLI云量少于10%的影像,冰川湖泊边界平均误差在±15 m以内。
2008-2017年亚洲高山冰川湖30 m分辨率数据集(Hi MAG数据集)[23]。该数据集应用了2008-2011年的Landsat5 TM影像、2012年的Landsat7 ETM+影像以及2013-2017年期间的Landsat 8 OLI云量少于20%的影像,该数据集验证精度达88%,用户精度达97%,生产精度达82%。
由于本文针对陆表上的积雪覆盖,在进行分类后处理时,需要将分类结果与冰湖数据进行合并,其中2013-2017年分别选用对应年份Hi MAG冰湖数据,2018-2020年均选用2018年亚洲高山冰湖数据。
1.2.3 河流与湖泊矢量数据
采用2010年全球30 m分辨率地表水数据集[24]为基础,以欧亚大陆的北极河流为研究对象,对经过预处理的矢量数据进行投影变换、拼接和数据裁剪,并利用GRWL全球河宽数据和SRTM 30 m数字高程数据用于识别每个细分区域中的河流[25]。
湖泊数据应用全球湖泊数据 Hydrolake数据[26],该数据集综合了加拿大水文数据集、美国国家水文数据集、欧洲流域和河网系统、全球湖泊和湿地数据库和全球水库大坝数据库等数据绘制全球湖泊数据集,约有143万个湖泊。经过广泛的人工目视验证,确保湖泊范围的准确性。
由于本文针对陆表上的积雪覆盖,所以将2013-2020年所有分类结果均应用位于喜马拉雅山区的河流和湖泊数据,将其与分类结果进行合并。
1.3.1 数据处理流程
基于上述所获得的Landsat 8原始数据,采用以下步骤开展积雪范围的提取,具体流程见图2。
1.3.2 样本选择规则
监督分类对于待研究对象或区域,需要选择训练样本建立分类标准。为保证地物类别信息提取,需要将其合并为RGB彩色影像。对比Landsat 8数据不同波段组合的目视效果,对于积雪信息的提取效果较好的为6、5、4(R、G、B)波段合成假彩色影像。
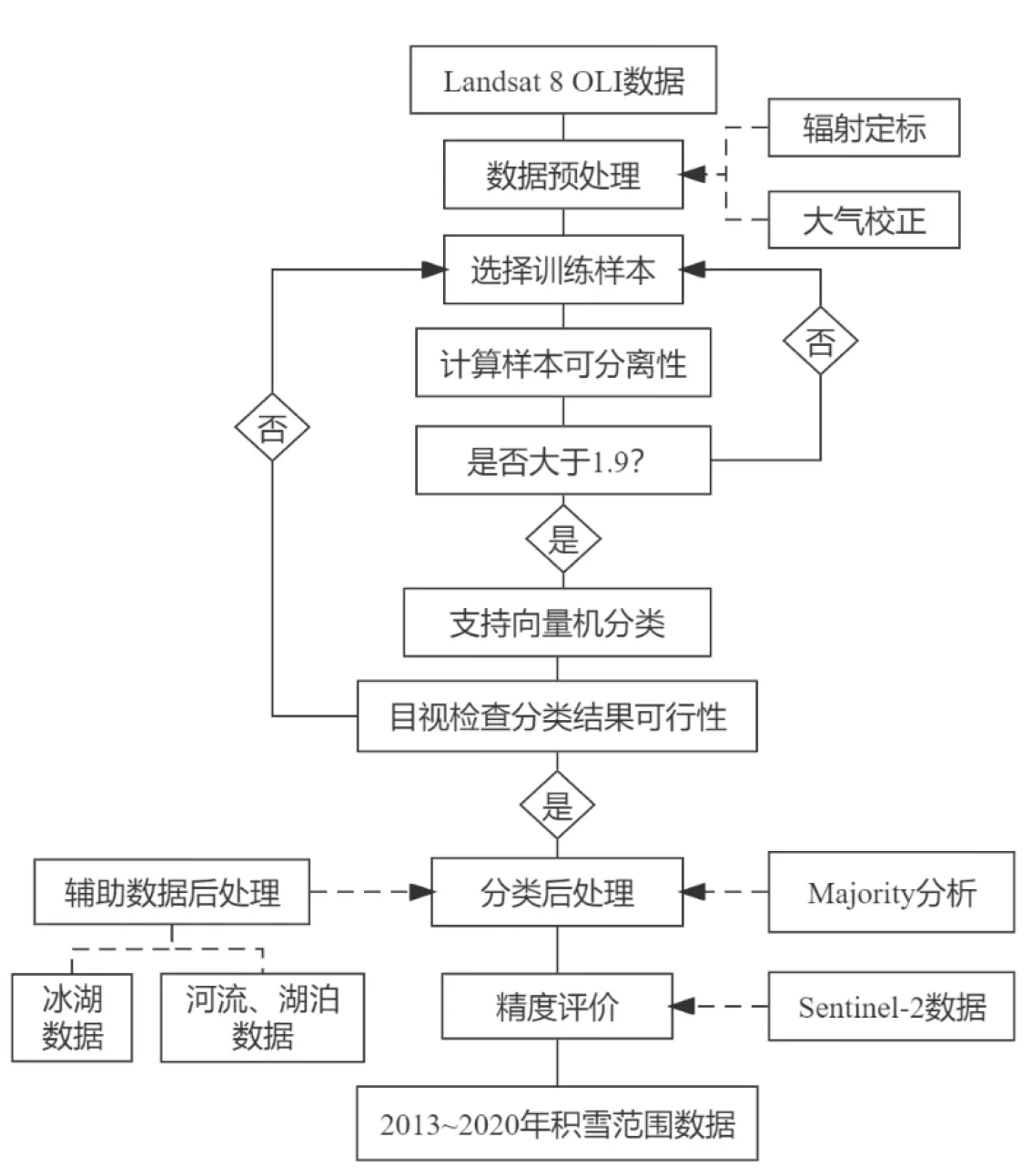
图2 基于Landsat影像积雪覆盖范围数据提取过程流程图Figure 2 Flowchart of data extraction process based on snow cover of Landsat imagery
训练样本的质量和数量对分类结果有重要影响,所以训练样本的选择应注意:选取各类目标地物面积较大的区域,每一种地物类别所选取的训练样本数据包括10个以上样本点[27],能够提供不同类别地物的足够信息,但也要保证训练样本的简洁不能过多。统计约100景影像后得出,一景影像内选取的积雪和非积雪两类地物的训练样本最好不超过80个。若样本数量控制在80个以内,在保证分类精度的基础上,每景影像处理时间达5-10分钟。样本选取越多数据处理速度越慢,实践证明当样本选到150-200个,数据处理时间高达20分钟以上,大大降低了数据处理效率。同时选取的训练样本要满足尽可能均匀分布整幅影像。
除以上的训练样本质量控制原则以外,本研究针对不同区域不同时期积雪训练样本总结出以下几点:
(1)无阴影区样本选取
选用的影像数据为云量小于10%的数据,图3展示了不同积雪覆盖区Landsat 8假真彩影像,其中积雪呈现青蓝色。在样本选取过程中,将不同类别地物的训练样本通过多次目视修正以及与Google Earth上高分辨率影像数据对比将训练样本分为单一训练样本和混合训练样本。对于单一的训练样本,基于目视解译对不同类别地物选取不同数量的单一训练样本,此次选取的有积雪、裸地、植被、云和山体阴影等(图3a);
对于混合像元区域的训练样本,适当选取位于边缘处的不同类别训练样本,本研究积雪混合像元主要选取位于积雪与裸地、积雪与植被、积雪与阴影边缘处(图3b、c)。

图3 无阴影区Landsat 8假彩色影像图(6、5、4波段)Figure 3 Unshadden landsat 8 false color image(6, 5, 4 bands)
(2)阴影区样本选取
在高原山区由于太阳高度角的不同,产生了不同范围的山体阴影,而基于遥感影像提取山体阴影区的积雪也是一个难点。针对喜马拉雅山阴影区积雪信息的提取,本研究主要根据Google Earth上高分辨率影像数据对山体阴影区积雪进行对比和人工目视纠正,来选取正确的积雪训练样本。
(3)同一地区不同时期样本选取
不同时期积雪的覆盖范围程度有很大的变化,需要根据积雪占比来调整训练样本的数量。图4中展示了喜马拉雅东段行列号为134040,2016年1月份、2月份、11月份和12月份同一区域的积雪覆盖情况。能够明显看出,在11月份和12月份积雪占比明显减少。就此,对于同一区域不同时期影像的单一训练样本和混合训练样本共选取10%左右作为恒定样本,其余根据影像中地物类型的变化进行适当调整。
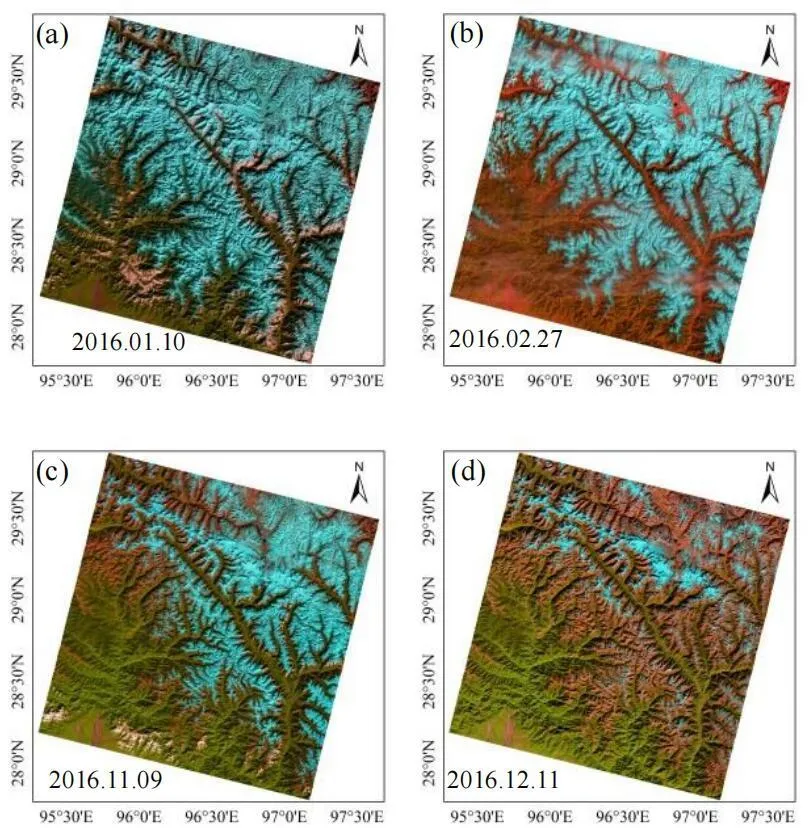
图4 不同时期Landsat 8假真彩影像图(6、5、4波段)Figure 4 Landsat 8 false true color image map in different periods (6, 5, 4 bands)
(4)非积雪区样本选取
在选取非积雪训练样本时由于喜马拉雅山地物类型较为复杂,除了积雪还有其他类型地物,如裸地、河流、湖泊、山体阴影、植被、云。当积雪占比较小时,非积雪地物类型较多,可以适当增加非积雪样本的数量。
为了保证样本选择的正确性,样本选择结束后需计算训练样本的分离性,即积雪与非积雪两类间的距离,类别间的统计距离主要是用J-M距离和转换分离度[28],得到的参数范围应介于0-2之间,如果参数大于1.9说明样本间可分离性比较好,属于符合要求的训练样本;
参数值小于1.8则需要重新选择样本,若参数值小于1要考虑样本合并。
1.3.3 监督分类方法
采用支持向量机监督分类方法,支持向量机(Support Vector Machine,SVM)通过核函数将原空间的特征向量非线性映射变换到高维特征空间并建立最优分类超平面[29],SVM比其他的分类器更高效的原因就在于通过核函数可以降低计算复杂度构造更复杂的分类器,来求解更复杂的问题,能够有效解决地形复杂的喜马拉雅山积雪信息提取问题。

选用高斯径向基函数(Radial Basis Function, RBF),该核函数是非线性分类SVM最主流的核函数,表达式如下:

γ为是高斯核函数唯一的超参数,默认为0.143,为表示向量的范数也可以理解为向量的模。
1.3.4 分类后处理
分类后处理是监督分类过程非常重要的一步,由于监督分类的结果会产生小面积图斑,结合积雪制图方法和实际情况,应需对监督分类结果进行分类后处理。
首先,对监督分类的结果运用人工目视解译的方法进行判读,少数影像会出现明显错分的地物,对此将根据先验知识对影像中错分的像元进行局部手动修改。若在初步分类没有将积雪像元与云像元很好地区分开来,在后处理步骤应用ENVI Classic对错分云像元进行手动剔除,进一步提高分类结果的质量。应用Majority分析方法对分类结果中小图斑进行去除或重新分类,得到小斑块去除的积雪覆盖范围影像,图5为2015年3月20日行列号142040区域分类后处理前后对比图,可看出分类后处理的影像小斑块明显减少。

图5 Majority分析分类后处理前后对比图Figure 5 Comparison before and after Majority analysis and classification processing
其次,由于喜马拉雅山的河流湖泊较多,为了以后更好地分析陆表不同年份、不同季节积雪面积的变化,本研究利用辅助数据将冰湖、河流和湖泊数据与分类结果进行合并,并将其赋予不同的像素值,得到最终的积雪覆盖范围产品数据集。
目前已有美国西部积雪覆盖数据产品,经过对比验证 SVM 方法在地形复杂的山区具有更好积雪识别效果。美国USGS积雪数据产品选用自1984年以来所有可用的Landsat TM、Landsat ETM+和Landsat OLI 空间分辨率30 m的影像数据进行雪盖制图。USGS Landsat积雪面积科学数据产品绘制了逐像素积雪覆盖率(FSCA)。应用邻域冠层调整算法[30],结合 30 m分辨率的美国国家土地覆盖数据库、2011年的土地覆盖和森林冠层百分比数据集和10 m分辨率的DEM数据,从Landsat地表反射率数据中计算出积雪面积覆盖率。
为验证 SVM 方法同邻域冠层调整方法在山区积雪提取结果差异性,随机选取多景位于美国西部山区且云量少于10%的Landsat OLI影像进行比对。通过目视解译的方法检验两种方法所得的结果(表2)。结果显示,SVM方法比邻域冠层调整方法在部分区域识别到的积雪更接近Landsat 8假彩色影像,邻域冠层调整方法存在少量漏分错分。

表2 积雪分类结果对比表Table 2 Comparison table of snow classification results

日期 云量 Landsat 8假真彩影像(6、5、4波段) SVM方法结果 邻域冠层调整方法结果2016.12.29 7.95%2016.12.29 7.95%2016.01.04 9.35%2017.01.27 0.19%images/BZ_281_754_422_1148_800.pngimages/BZ_281_1253_422_1647_800.pngimages/BZ_281_1754_422_2148_800.pngimages/BZ_281_754_814_1148_1192.pngimages/BZ_281_1253_814_1647_1192.pngimages/BZ_281_1754_814_2148_1192.pngimages/BZ_281_754_1206_1148_1584.pngimages/BZ_281_1253_1206_1647_1584.pngimages/BZ_281_1754_1206_2148_1584.pngimages/BZ_281_754_1598_1148_1976.pngimages/BZ_281_1253_1598_1647_1976.pngimages/BZ_281_1754_1598_2148_1976.png
在植被覆盖率较高的区域,分别选取位于洪堡-托伊亚比国家森林、美国黄石国家公园等Landsat 8影像(表3),通过目视解译能够看出,被植被冠层遮挡区域的积雪,USGS产品运用邻域冠层调整的方法相对于本研究的方法提取到更多位于森林覆盖下的积雪。

表3 植被覆盖率较高地区积雪分类结果对比表Table 3 Comparison table of snow classification results in areas with high vegetation coverage

日期 云量 Landsat 8假真彩影像(6、5、4波段) SVM方法结果 邻域冠层调整方法结果2020.12.05 0.43%2016.03.18 7.95%images/BZ_282_754_422_1148_800.pngimages/BZ_282_1253_422_1647_800.pngimages/BZ_282_1754_422_2148_800.pngimages/BZ_282_754_814_1148_1192.pngimages/BZ_282_1253_814_1647_1192.pngimages/BZ_282_1754_814_2148_1192.png
基于 Landsat 8喜马拉雅山脉中段和东段高分辨率积雪覆盖数据集的命名遵循如下规则:
HIL8_X_SCE_HHHVVV_YYYYMMDD_V1.tif,其中:
(1) HI:喜马拉雅山(Himalaya);
(2) L8:Landsat 8;
(3) X:位置(E代表喜马拉雅山东段,C表示喜马拉雅山中段);
(4) SCE:积雪覆盖范围;
(5) HHH:Landsat行号;
(6) VVV:Landsat列号;
(7) YYYY:表示年份;
(8) MM:表示月份;
(9) DD:表示具体日期;
(10) V1:表示第一版本。
例如:HIL8_E_SCE_134040_20131117_V1.tif,表示喜马拉雅山东段2013年11月17日行列号为134040的 Landsat 8积雪数据产品。
本套Landsat 8积雪覆盖范围数据集中像素值表示信息如下。详细信息如表4所示。
喜马拉雅山东段样本:图6a、b为134040区域积雪提取结果,c、d为137041区域提取结果,两组图积雪覆盖范围在同月不同年份有减少的趋势。
喜马拉雅山中段样本:图6中的 e、f为行列号为 141040区域积雪提取结果,g、h为行列号143039区域的积雪提取结果,两组积雪覆盖范围在同年不同月份,积雪覆盖范围有很大变化。

表4 数据集影像分类描述表Table 4 Dataset image classification description table
获取位于喜马拉雅山中段和东段4景空间分辨率为10 m的Sentinel-2数据作为参考数据对本数据进行验证。为满足时间和空间均匀分布,数据分别为2017年1月19日行列号为135040喜马拉雅山东段、2019年1月24日行列号为144039喜马拉雅山中段、2018年3月10日行列号为144039喜马拉雅山中段和2019年5月9日行列号为143040喜马拉雅山中段Sentinel-2数据。对Sentinel-2数据使用相同方法提取积雪像元,评估Landsa 8在积雪边缘区的识别精度。为保证每个网格中两种数据的面积相同,创建900×900 m格网,选取位于积雪边缘区的格网,通过计算两种结果每个网格中的积雪占比得出评估结果。

图6 喜马拉雅山中段和东段积雪范围产品示例图Figure 6 Product samples in the snowy range of the middle and eastern Himalayas
均方根误差(RMSE)反映观测数据与参考数据在边缘区的误差(网格对网格),可采用下面公式表示:

N代表样本的数量,xi代表观测数据即 Landsat每个网格中积雪占比,yi代表为参考数据即Sentinel-2每个网格中的积雪占比,单位为每/格网积雪占比。
相关系数(r)反映两个数据之间的相关性,可采用下面的公式表示:

x̅代表观测数据平均值即Landsat平均每个网格中积雪占比,y̅代表参考数据平均值即Sentinel-2平均每个网格中的积雪占比。
表5显示Landsat与Sentinel-2相关系数均在0.95以上,均方根误差在0.1左右,说明30 m分辨率Landsat 8与10 m分辨率的Sentinel-2积雪数据具有较高的一致性。

表5 拟合优度、相关系数和均方根误差Table 5 Goodness of fit, correlation coefficients, and root mean square errors
通过对网格内两种数据结果进行线性拟合,图7显示Landsat与Sentinel-2拟合结果R²均在0.9以上,趋势线斜率接近1,拟合效果较好。Landsat在1、3月份存在高估现象,在5月份(图7d)出现轻微低估现象,考虑可能是由于5月份瞬时积雪已基本消融,可供选取积雪网格数量较少导致Landsat出现低估。


图7 用Sentinel-2积雪分类结果验证Landsat 8积雪覆盖范围数据散点图Figure 7 The scatter plot of landsat 8 snow cover data verified by the Sentinel-2 snow classification results
数据集共享了喜马拉雅山中段和东段地区2013-2020年高分辨率积雪覆盖范围数据,文件存储为tif格式,用户可以根据不同区域和年份选择下载。数据集可以反映喜马拉雅山积雪覆盖范围的变化特征,也适用于喜马拉雅山脉及下游地区水资源管理、生态效益和洪涝灾害等问题的研究。对于喜马拉雅山脉气候变化研究、长时间序列积雪变化分析和未来预测提供重要参考,也可为中低分辨率积雪数据产品的验证和降尺度提供样本数据。
致 谢
感谢美国地质调查局(USGS)提供Landsat 8数据产品以及欧洲航天局(ESA)提供的Sentinel-2数据产品。
猜你喜欢东段喜马拉雅山覆盖范围东昆仑东段化探采样方法找矿效果探讨——以青海科日南地区为例矿产勘查(2020年2期)2020-12-28陈维山书香两岸(2020年3期)2020-06-29色尔腾山山前断裂东段与西段转折处构造演化特征震灾防御技术(2019年3期)2019-06-02基于机器学习的基站覆盖范围仿真电脑与电信(2018年11期)2018-02-16西藏喜马拉雅山东南麓禁猎后的弓箭使用方式——以陈塘夏尔巴人为例西藏研究(2016年5期)2016-06-15浅谈提高小功率短波电台覆盖范围的措施电子制作(2016年23期)2016-05-17关于短波广播覆盖范围的几点探讨科技视界(2016年9期)2016-04-26微剧本·喜马拉雅山上的鱼文学少年(原创儿童文学)(2016年19期)2016-02-28南昌市前湖大道快速路东段工程方案比选城市道桥与防洪(2014年7期)2014-02-27搜集狂与预言家中国校外教育(上旬)(2006年7期)2006-07-21扩展阅读文章
推荐阅读文章
老骥秘书网 https://www.round-online.com
Copyright © 2002-2018 . 老骥秘书网 版权所有