孙林慧 张 蒙 梁文清
(南京邮电大学通信与信息工程学院,江苏南京 210003)
近年来,深度学习技术广泛地用于信号分离中,学者们提出多种基于深度学习的语音分离方法[1-2]。对单通道语音分离的研究包括说话人语音分离、语音和噪声分离[3]、歌声分离等,主要通过对目标语音和干扰语音进行时频域分析,从混合信号中提取出目标语音。基于神经网络的语音分离根据训练目标可分为基于映射的方法和基于掩码的方法[4]。基于映射的方法直接将纯净语音频谱作为输出目标。目前语音分离大多使用基于掩码的方法。Wang 等人使用理想二值掩码(Ideal Binary Mask,IBM)和理想比率掩码(Ideal Ratio Mask,IRM)作为深度神经网络(Deep Neural Network,DNN)的训练目标时,发现IRM 的分离性能优于IBM 的[5-6]。Zhang 等人提出一种深度集成神经网络的语音分离方法,该方法充分利用了上下文信息,使估计的IRM 更加准确[4]。为了同时增强幅度和相位谱,Williamson 等人提出采用复数IRM(Complex Ideal Ratio Mask,CIRM)作为训练目标[7],用DNN 同时训练CIRM 的实部和虚部来进一步提高语音分离的性能。
随后学者们对网络模型进行了各种优化。Nie等人提出将DNN 和非负矩阵分解(Non-negative Ma⁃trix Factorization,NMF)结合在一个框架下,使用DNN 预测NMF 的权重矩阵,与字典矩阵相乘得到增强后的语音幅度谱,降低了计算误差[8]。受卷积神经网络(Convolutional Neural Network,CNN)在图像识别大获成功的启发,一些学者使用CNN 在时频域建模进行语音分离。Fu 等人提出了一种感知信噪比的CNN 语音增强方法,并证实CNN 能够有效提取语音信号的局部时频特征,从而得到比DNN 更好的语音增强性能[9]。范存航等人提出一种基于编解码器的卷积神经网络用于端到端的语音分离,在单输出网络的loss函数中引入干扰语音信息以优化网络模型[10]。之后又有学者提出各种复杂结构的深度神经网络用于语音分离。Huang等人在循环神经网络(Recurrent Neural Network,RNN)中将比率掩码融合到幅度谱的估计中[11],使估计语音的幅度谱更加准确。为了解决RNN 的梯度消失问题,一些学者提出应用长短时记忆网络(Long Short-Term Memory,LSTM)建模,实现语音分离[12-14]。王志杰等人将双路径循环神经网络(Dual Path Recurrent Neu⁃ral Network,DPRNN )应用到单通道语音增强中,该复合网络结构由CNN 和LSTM 组成,更适合对长序列语音数据建模[15]。王涛等人提出了一种基于生成对抗网络(Generative Adversarial Network,GAN)联合训练的语音分离方法,在训练中同时考虑两个说话人的语音信息,有利于GAN 得到丰富的语音信息[16]。这些研究工作都通过训练各种深度神经网络得到输入混合语音特征与目标语音特征之间的非线性映射关系来实现语音分离,相比浅层模型,深度学习方法解决单通道语音分离问题更具有优越性。
针对两个说话人混合语音分离问题时,通常按照说话人混合情况分别讨论,说话人混合包括异性别混合(Male-Female,M-F)和同性别混合,同性别混合又包括男男混合(Male-Male,M-M)和女女混合(Female-Female,F-F)。以往的语音分离研究均是按照性别组合分别讨论,即直接在匹配的模型上进行语音分离,但是现实语音分离时混合语音的性别组合是未知的。若先判断出混合语音性别组合情况,再根据相应的模型进行语音分离,这样更适用于实际的语音分离。Du 等人提出两阶段的DNN 语音分离系统,通过聚类分析对性别组合进行划分[17],对说话人组合检测后根据匹配的DNN网络进行语音分离。受其启发,本文首先通过建立更精确的模型解决混合语音性别组合分类问题,然后再进行语音分离。
判断说话人性别组合属于说话人识别领域的一个问题。近年来,说话人识别技术[18-21]已经飞速发展,基于深度学习的说话人识别方法逐渐成为主流[22-23]。深度学习相对于传统方法的主要优势是其强大的表征能力,能够从话语中提取高度抽象的嵌入特征用于识别说话人。由于在大多数情况下,混合语音中两个人的语音同时存在,训练模型时异性别组合与两种同性别组合中都有一种共同性别语音存在,这使得混合语音性别组合识别比传统的纯净语音说话人识别要难得多,使用传统单一声学特征直接识别三种性别组合非常困难,很容易产生误判。
针对未知性别组合混合语音的分离问题,本文提出深度特征融合的策略,应用CNN-SVM 的框架判断未知混合语音的性别组合。使用CNN 的局部感知特性提取梅尔频率倒谱系数和滤波器组特征的深度特征,融合两种深度特征来弥补单一声学特征区分能力不足的缺陷,该深度融合特征可以深度挖掘分类特征中性别组合类别信息。然后利用支持向量机(Support Vector Machine,SVM)分类器判别性别组合,最后根据分类结果选择对应说话人性别组合的模型进行语音分离。与使用通用的语音分离网络相比,针对不同的性别组合分别训练相应的语音分离网络,每种网络的针对性更强,网络需要学习的参数更少,可以进一步提升语音分离效果。
本文主要内容如下:第2 节描述了本文提出的基于卷积神经网络-支持向量机的性别组合分类方法,第3 节描述本文所采用的基于深度神经网络的语音分离网络。第4 节是本文的实验部分,首先分析特征和分类器对识别性能的影响,再根据最佳的分类结果选择对应性别组合的CNN/DNN 模型进行语音分离,并分析结果证实本文所提方法的有效性。第5节对全文进行总结。
实际语音分离时,由于混合语音的说话人性别组合相关信息往往未知,若直接在普适的模型上进行语音分离,其效果欠佳。针对未知性别组合混合语音的分离问题,本文提出基于CNN-SVM 性别组合分类的语音分离方法,其框图如图1所示,主要包括三个模块。第一个模块挖掘具有性别组合区分能力的深度特征,首先对混合信号进行预处理,计算梅尔频率倒谱系数(Mel Frequency Cepstrum Coef⁃ficients,MFCC)和滤波器组特征(Filter bank,Fbank)的特征参数,然后通过2 个训练好的卷积神经网络模型分别提取MFCC 特征和Fbank 特征的深度特征,并将这两种深度特征进行融合,形成最终的分类特征。第二个模块基于分类特征利用SVM 分类器对混合语音性别组合进行识别。第三个模块选择对应性别组合的分离模型进行语音分离。

图1 基于CNN-SVM性别组合分类的语音分离框图Fig.1 Block diagram of speech separation based on CNN-SVM gender combination classification
相比DNN,CNN 中具有的卷积层可以提取局部区域特征,能够很好地保留特征的空间信息,因此本文采用CNN 构建说话人性别组合的深度特征抽取模型。本文提出的基于CNN-SVM 的混合语音性别组合识别包括训练阶段和测试阶段,如图2所示。首先生成三种性别组合混合语音,在训练阶段,对训练的混合语音进行预处理,并计算出相关声学特征,训练基于CNN 的深度特征提取模型,再基于深度特征训练SVM 分类器。在测试阶段,未知性别组合的测试样本经过预处理后,通过训练好的卷积神经网络模型提取出深度特征,将测试语音深度特征基于SVM模型预测性别组合识别结果。

图2 基于CNN-SVM的混合语音性别组合识别框图Fig.2 Block diagram of mixted speech gender combination dectection based on CNN-SVM
本文所使用的卷积神经网络的具体结构如图3所示,整个网络由输入层、2 个卷积层、2 个池化层、2 个全连接层和输出层构成。卷积层、池化层和全连接层的数目可根据训练数据量设定。

图3 卷积神经网络基本结构Fig.3 Architecture of convolutional neural network
卷积层是卷积神经网络的核心,通过输入特征与卷积核加权求和计算出该层的输出,如式(1)所示。

式(1)中:vl为第l层的特征,wl为第l层的卷积核权重系数,‘*’为卷积操作,vl-1为第l-1 层的特征,bl为第l层的偏置系数,本文分类模型中将原始输出值通过Relu 激活函数增加网络的非线性。卷积运算使输出数据中的任何一个单元都只与输入数据的一部分相关,可以用来提取说话人的局部特征。而核的大小远远小于输入的大小,所以卷积运算大大降低了网络参数。
在卷积层后面设置一个池化层,进行特征选择,一般包括均值池化和最大值池化方法。在说话人识别领域中,一般认为最大值池化性能更好[24]。本文选择最大值池化方法,保留该区域最有效的信息。
本文所使用的第一层的卷积核的大小是3 × 3,卷积核个数为32,池化核的大小是2 × 2,步长是2。第二层的卷积核的大小是3 × 3,卷积核个数为48,池化核的大小是2 × 2 的,步长是1。由于卷积核、池化核数量较多,池化层后展平的输出特征维数很大,通常在之后设置全连接层,将卷积、池化后的特征进行整合,具体过程如式(2)所示。
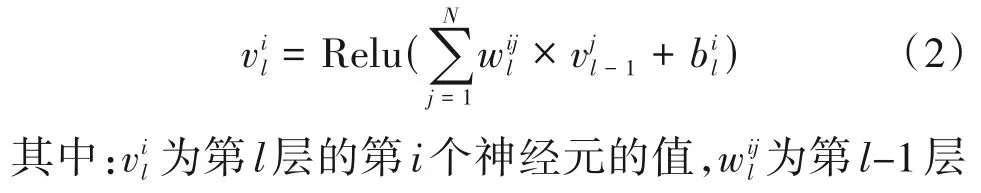

由于本文是三分类的任务,输出层包含三个节点,分别表示男-男语音、男-女语音、女-女语音三种类别的概率,选择Softmax 作为输出层的激活函数,如式(3):
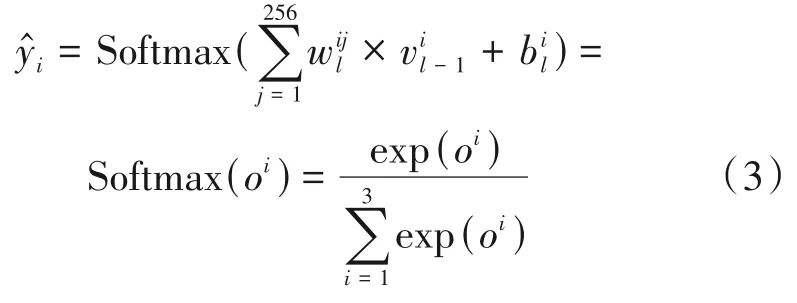
其中,i∈{1,2,3},与式(2)类似,输出层的原始输出值oi根据权重系数与前一层的输入向量相乘加上偏置计算得到,oi表示三个类别在(-∞,+∞)范围内的原始输出分数值,exp(oi)表示通过e指数将oi映射到(0,+∞),表示exp(oi)归一化后的输出,是各个性别组合的分布概率,网络的预测目标是具有最大概率值的神经元。
训练基于CNN 的深度特征提取模型,包括了前向传播(Forward Propagation,FP)和反向传播(Back⁃ward Propagation,BP)两个阶段。FP阶段是对权重和偏置进行随机初始化,从输入层开始,根据式(1)~式(3),逐层计算,最终得出输出层的预测结果。BP阶段,根据式(4)计算交叉熵损失函数值,采用梯度下降算法约束损失函数,逐步优化模型各层的权重w和偏置b。
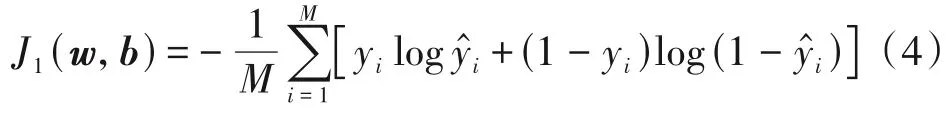
其中,yi表示第i种性别组合的正确类别,表示CNN 预测的第i种性别组合的标签,此处M=3,代表一共有三种性别组合。
在进行分类之前,输入到网络模型中的语音特征要尽可能包含较多说话人信息。梅尔频率倒谱系数、滤波器组特征参数是目前说话人识别中使用广泛的特征参数[22]。两种特征的计算方式如图4 所示。梅尔频率倒谱系数是为使语音特征与人耳的听觉特性相吻合设计出的手工特征。通常使用39 维的MFCC 特征,包括静态信息和动态信息,由13 维MFCC、13维一阶差分谱、13维二阶差分谱构成。通常使用40维的Fbank特征。由于提取Fbank特征参数时缺少一步离散余弦变换(Discrete Cosine Trans⁃form,DCT),Fbank 特征维数比MFCC 高,具有更多的局部特征和原始特征。在特征方面考虑了符合人耳特性和保留原始特性的特征。其他的相关声学特征,例如线性预测系数(Linear Prediction Coeffi⁃cient,LPC)早在70 年代提出,易于实现但对误差比较敏感。线性预测倒谱系数(Linear Prediction Cepstral Coefficient,LPCC)是LPC 特征的改进,对元音的描述能力强但对辅音描述能力弱,现阶段MFCC、Fbank 描述语音发声的特性更好。为了深度挖掘性别组合类别区分性的信息特征,利用2 个CNN 分别提取MFCC 和Fbank 特征的深度特征,并融合这两种深度特征作为最终的性别组合分类特征。
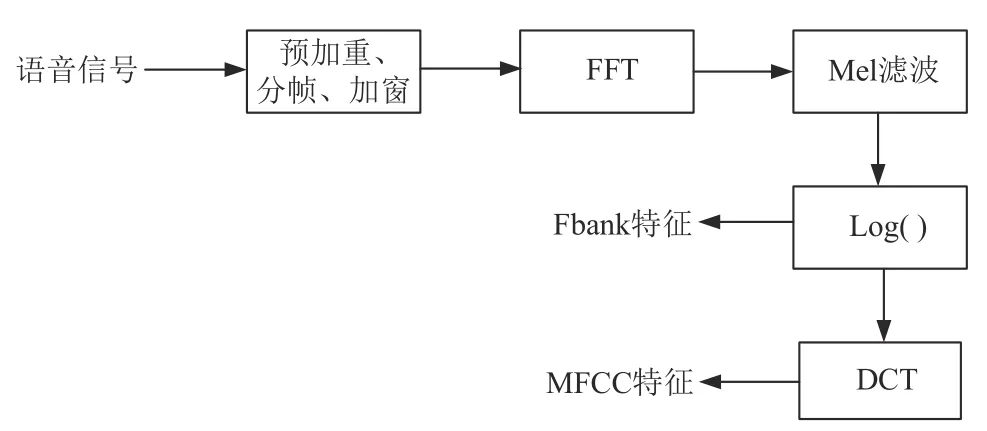
图4 MFCC和Fbank特征计算过程Fig.4 Calculation process of MFCC and Fbank feature
基于CNN-SVM 的混合语音性别组合识别的具体流程见表1,包括训练和测试两个阶段。在训练阶段,首先生成三种性别组合混合语音,分为男-男混合、女-女混合、男-女混合,提取三种混合语音的39 维MFCC 特征和40 维Fbank 特征,将三种混合语音的MFCC 和Fbank 特征分别作为两个CNN 的输入,在式(4)损失函数的约束下训练CNN。然后将混合语音的MFCC 和Fbank 特征分别输入到训练好的CNN,分别取出第一个全连接层的特征,即得到MFCC 特征和Fbank 特征对应的1024 维的深度特征,记为DMFCC 和DFbank。需要说明的是,第一个全连接层比第二个全连接层的特征维数更高,包含更多信息,将第二个全连接层作为与输出层之间的过渡层,而池化层的输出特征还未经过整合,区分性比起全连接层较差,所以将第一个全连接层作为深度特征提取层。至此经过多个卷积池化操作,整个网络的特征维数变小,相比原始的MFCC 和Fbank 特征,此时的深度特征是一种更抽象、更凝练、更具区分性的特征表现形式。考虑不同特征之间的互补性,将两种特征向量进行串行融合,即水平连接,得到2048 维的深度融合特征,记为DMFCC+DFbanktrain,该融合特征包含更多性别组合类别信息。最后基于该融合特征训练SVM 分类模型。

表1 基于CNN-SVM的混合语音性别组合识别的具体流程Tab.1 Specific steps of mixted speech gender combination dectection based on CNN-SVM
t 分布-随机邻域嵌入(t-SNE)有助于分析各种特征对于分类检测的有效性[25],本文利用t-SNE 分析MFCC、Fbank、DMFCC、DFbank 和DMFCC+DF⁃bank 特征对于混合语音性别组合检测的有效性。图5(a)、(b)是三种类别混合语音原始的MFCC 和Fbank 特征使用t-SNE 降维的特征分布图,图6(a)、(b)、(c)是三种类别混合语音的DMFCC 特征、DF⁃bank特征和DMFCC+DFbank 特征的分布图,三种颜色代表三种类别。从图5 可以看出原始的MFCC 特征和 Fbank 三种类别的特征分布比较杂乱,不易区分。从图6(a)、(b)可以看出,经过CNN 的多层卷积、池化得到的DMFCC 特征和 DFbank 特征,三种类别具有一定的区分度,证实了使用CNN 提取的DMFCC 特征和 DFbank 特征进行性别组合分类的可行性。将图6(a)、(b)与图6(c)比较,发现DMFCC+DFbank 特征在三种类别之间的区分性最大,表明深度融合特征最具有性别组合区分力。
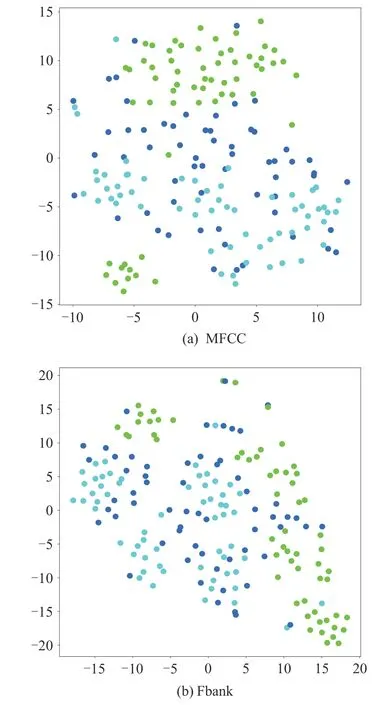
图5 原始MFCC和Fbank特征的t-SNE可视化结果Fig.5 T-SNE visualization of raw MFCC and Fbank

图6 两种深度特征和融合特征的t-SNE可视化结果Fig.6 T-SNE visualization of two deep features and fusion feature
为了更好地对性别组合信息进行分类,利用支持向量机分类器取代 CNN 的Softmax 分类器。使用的分类决策函数为[26]:

其中,sign(⋅)为符号函数,yi是样本的标签,ϖi=aiyi为权值,x是训练样本的深度融合特征DMFCC+DF⁃banktrain,β为输入数据的截距,K(xi,x)为核函数,选择使用最广泛的径向基核函数。N为训练的样本数目。
其中,ai,i=1,2,…,N通过下列优化问题的解求得:

其中,β通过式(7)求得:

在测试阶段,利用训练阶段训练好的CNN 获得未知性别组合混合语音的深度特征,融合得到深度融合特征DMFCC+DFbank,输入到训练好的SVM中,预测测试语音的性别组合,指导后续的语音分离模块选择匹配的分离模型。
本文考虑的信号模型为两个时域信号相加,属于单通道语音分离:

其中,s1(t)和s2(t)分别表示两个说话人语音信号,y(t)表示混合语音信号。基于深度学习的语音分离通常在频域进行研究,通过短时傅里叶变换(Short Time Fourier Transform,STFT)将式(8)转化到频域分析:

其中,Y(k,f)、S1(k,f)、S2(k,f)代表时域信号y(t)、s1(t)、s2(t)在第k帧时的短时傅里叶变换。本文所采用的基于DNN/CNN 的语音分离模型的整体框图,如图7。在训练时,网络的输入是混合语音的幅度谱,目标语音信号si(t)的IRM用式(10)计算:

图7 基于DNN/CNN的语音分离模型Fig.7 DNN/CNN based speech separation model
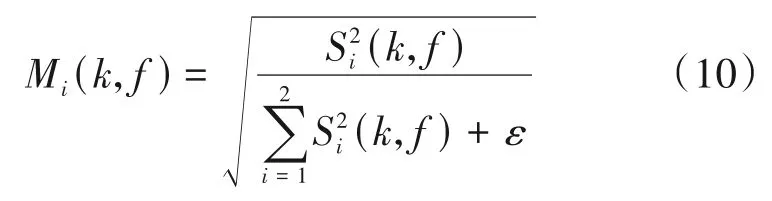
在分母上加上了一个极小的正数ε,以避免分母为0。
采用最小均方误差损失函数约束网络的训练,以最小化目标语音的IRM 与估计比率掩码(Ratio Mask,RM)之间的误差:

其中,K表示语音分帧的总数目,通过DNN/CNN 学习映射关系f(⋅)得到表示所估计的第k帧目标说话人的比率掩码矩阵。最小均方误差使用l2范数衡量。在语音分离阶段,通过训练好的网络,输入混合语音信号幅度谱特征矩阵Y,获得目标语音信号的估计比率掩码,并根据式(12)与混合信号幅度谱特征矩阵做哈达玛乘积,从而获得估计的目标语音信号幅度谱特征矩阵根据式(13),将与混合信号的相位φ结合写为复数信号,利用逆短时傅里叶变换(Inverse Short-Time Fourier Trans⁃form,ISTFT)重构估计的语音时域信号。

实验使用GRID 英文语料库对本文语音分离方法的性能进行验证。该语料库共包含34 名说话人(18 位男性和16 位女性),每位说话人有1000 句语音,每条语音为1~2 秒左右。本文语音分离模型的训练数据随机选择两个说话人,从语料库中随机抽取两位男性说话人(M1、M2)和两位女性说话人(F1、F2)两两组合用于训练和测试。训练语句由前500条语句组成,剩余语句作为验证集和测试集,选择100 条语句作为验证集,60 条语句作为测试集。随后生成混合语音,男-男性别组合表示为M-M,女-女性别组合表示为F-F,男-女性别组合由两位男性说话人和两位女性说话人语音组合生成,表示为M-F。
在混合语音性别组合判别阶段的卷积神经网络采用TensorFlow 深度学习框架构建,网络的结构2.1 节已经描述过,语音的采样率为16 kHz,FFT 点数为512,加汉明窗,窗长也是512,帧移长度是窗长的1/2。计算出39 维MFCC 和40 维Fbank 两种特征参数,并对特征都进行了归一化。使用随机梯度下降算法(Stochastic Gradient Descent,SGD)训练网络,学习率设置为0.01,训练时批次大小为16,迭代周期为200。采用的性能评价指标为识别率。MFCC 深度特征记为“DMFCC”,Fbank 深度特征记为“DFbank”,浅层融合特征记为“MFCC+Fbank”,深层融合特征记为“DMFCC+DFbank”。
4.1.1 特征对识别性能的影响
为了验证本文使用CNN 提取深度特征的有效性,使用直接计算出的特征与深度特征作为 SVM的输入进行性别组合分类,分析特征对识别性能的影响。基于MFCC、Fbank、浅层融合特征MFCC+Fbank、DMFCC、DFbank 和深层融合特征 DMFCC+DFbank 的性别组合分类性能如表2 所示。DMFCC与MFCC 相比,性别组合分类平均识别率提升20.55%;
DFbank 与Fbank 相比,平均识别率提升21.11%。可以看出通过卷积神经网络提取的深度特征相比浅层特征,可以更好地表征性别组合信息。另外,DMFCC+DFbank 的性别组合分类效果最佳,比MFCC+Fbank 提升19.44%,比DMFCC 提升3.34%,比DFbank 提升1.67%。可以看出直接将计算得到的浅层特征进行分类,识别效果很差,不利于后续的语音分离;
而DMFCC+DFbank 包含更多深层次的性别组合信息,有助于后续进行准确的语音分离。同时还发现同性(M-M、F-F)说话人的识别率比异性说话人(M-F)的识别率要高,异性说话人语音中既包括男性语音又包括女性语音,更容易误判为其他性别组合类别。
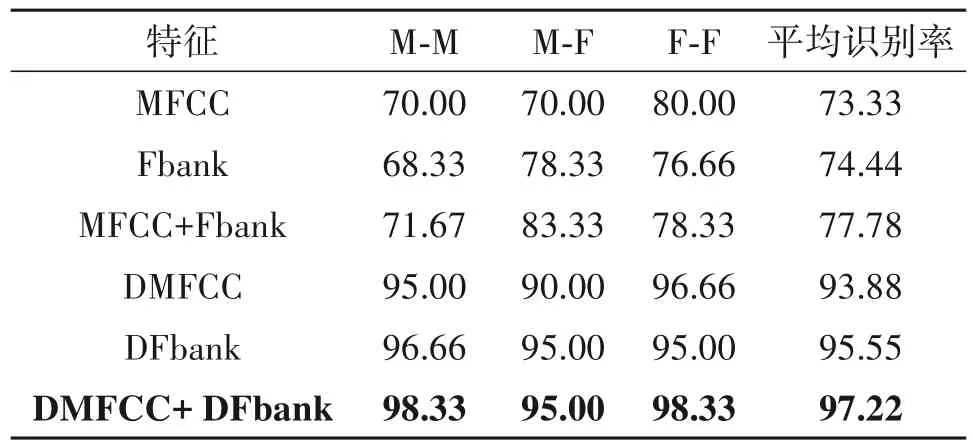
表2 不同特征在SVM下的识别率(%)Tab.2 Accuracy of different features using SVM(%)
4.1.2 分类器对识别性能的影响
为了验证深度特征在不同分类器下的识别性能,将CNN-SVM 模型与CNN-Softmax 对混合语音性别组合分类效果进行比较。实验结果如表3 所示,基于DMFCC、DFbank 和DMFCC+DFbank 特征,SVM比Softmax 的平均识别率分别提高0.58%、0.55%、2.78%。表明基于CNN 提取深度特征后使用SVM分类器要优于传统Softmax 分类的性能,CNN-SVM模型更适合性别组合分类。
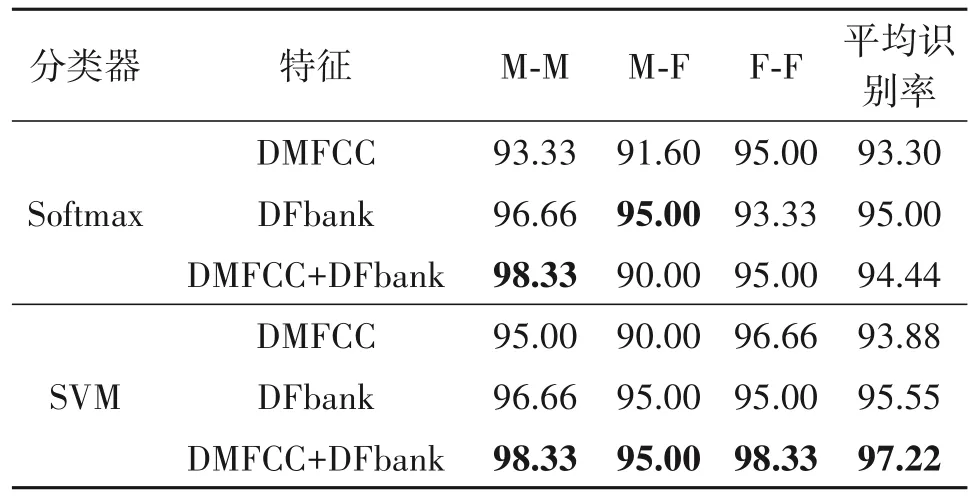
表3 深度特征在不同分类器下的识别率(%)Tab.3 Accuracy of deep features using different classifiers(%)
4.1.3 噪声对识别性能的影响
为验证本文性别组合分类方法的鲁棒性,在语音混合信号中加入加性噪声干扰。噪声使用NOISEX 数据集,实验中采用了白噪声(white)、战斗机噪声(F16)、车辆噪声(volvo)三种噪声,以-5 dB、0 dB、5 dB、10 dB、15 dB 的信噪比生成含噪混合语音。根据图8可以看出,在信噪比为-5 dB、0 dB 时,所提方法性能对噪声较为敏感。在信噪比为-5 dB的volvo噪声下的平均识别率为85%,识别率相比无噪声干扰时急剧下降。在信噪比为5 dB、10 dB、15 dB 时,识别率与无噪声干扰时的识别率差距逐渐减小。在信噪比为5 dB 时,三种噪声的识别率在91.11%以上。在信噪比为10 dB,三种噪声的识别率在92.78%以上。在信噪比为15 dB,三种噪声的识别率在93%以上,本文的混合语音性别组合分类方法对白噪声的鲁棒性最好,识别率为95.55%,可正确识别出大部分语句的性别组合。下一步的研究方向可考虑有背景噪声时的语音分离,本文语音分离阶段的实验中不添加背景噪声仅对干净语音进行分离。

图8 在不同噪声和信噪比下的识别性能对比Fig.8 Performance comparison under different noise and SNR
4.1.4 与其他方法的对比实验
为了更好的验证本文所提CNN-SVM 的识别方法的性能,将本文识别方法与文献[17]基于性别组合能量比判别的RDNN 方法进行性能对比。从表4可以看出,CNN-SVM 的识别率在F-F 组合中略低于RDNN,其他两种性别组合和平均识别率均高于RDNN。从平均识别率来看,本文的CNN-SVM 优于RDNN 方法,主要因为本文所提的深度融合特征区分力更强。
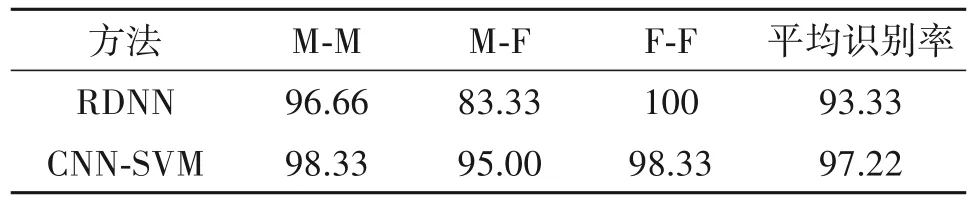
表4 不同方法的识别率(%)Tab.4 Accuracy of different methods(%)
语音分离阶段,STFT 的点数为512,加汉明窗,窗长与点数一致为512,帧移长度是窗长的1/2。采用pytorch搭建深度神经网络,使用SGD算法训练网络,学习率设置为0.01。DNN 网络的结构为257-1024-1024-1024-257,各层数值分别是各层的神经元个数,前几层的激活函数使用Relu,输出层使用Sigmoid。在训练时批次大小为128,迭代周期为200。一维CNN 网络的第一个和第二个卷积层的卷积核大小都是1×3,步长分别是1 和2。第一个和第二个池化层的池化核大小为1×3,步长为1,使用均值池化。全连接网络的结构是1024-1024-257,同样设置前几层的激活函数使用Relu,输出层使用Sig⁃moid。训练好三种性别组合的语音分离网络,将网络模型的权重参数保存下来,在测试阶段,依据性别组合分类结果选择对应语音分离模型。采用的语音评价指标为PESQ、STOI 和SDR,数值都与语音分离的性能呈正相关。
本节对本文提出的语音分离方法与选用匹配的、不匹配分离模型和通用语音分离模型在 DNN和CNN 上进行实验对比。混合语音经过本文提出的方法性别组合分类之后使用相应训练好的网络进行语音分离,记为“classify”。在性别组合正确对应的分离模型进行语音分离,记为“matched”。将分类结果在不匹配的语音分离网络上进行分离,记为“交叉测试”,即:如果分类结果为男-男混合(M-M),则使用女-女(F-F)对应的语音分离模型;
如果分类结果为女-女混合(F-F),则使用男-男说话人(M-M)对应的语音分离模型;
如果分类结果为男-女混合(M-F),使用男性说话人组合(M-M)对应的语音分离模型。最后各种性别组合通用的语音分离模型,该模型训练数据包括三种性别组合的语音,记为“baseline”。
4.2.1 男-女混合语音在不同分离模型下的分离性能比较
M-F 性别组合混合语音的分离实验结果如图9所示。classify-DNN与matched-DNN的PESQ、STOI、SDR 指标上只相差0.029、0.006、0.058 dB,classify-CNN 与matched-CNN 的PESQ、STOI、SDR 指标上只相差0.049、0.001、0.056 dB,表明分类后的语音分离效果和完全匹配的语音分离性能十分接近。classify-DNN 比交叉测试-DNN 的PESQ、STOI、SDR指标高0.584、0.262、4.163 dB,classify-CNN比交叉测试-CNN的PESQ、STOI、SDR指标高0.239、0.079、4.133 dB,表明classify 与交叉测试分离效果相比,优势较大。classify-DNN 比baseline-DNN 的PESQ、STOI、SDR指标提升0.279、0.002、0.980 dB,classify-CNN 比baseline-CNN 的PESQ、STOI、SDR 指标提升0.051、0.011、0.324 dB,表明本文的语音分离模型比通用的baseline网络性能更好。

图9 M-F性别组合在DNN和CNN分离网络下的分离性能Fig.9 Performance of speech separation based on DNN/CNN for M-F mixtures
4.2.2 男-男混合语音在不同分离模型下的分离性能比较
M-M性别组合混合语音的分离实验结果如图10所示。classify-DNN与matched-DNN的PESQ、STOI、SDR 指标上只相差0.017、0.008、0.564 dB,classify-CNN 与matched-CNN 的PESQ、STOI、SDR 指标上只相差0.030、0.006、0.213 dB。classify-DNN 比交叉测 试-DNN 的PESQ、STOI、SDR指标高0.354、0.221、3.110 dB,classify-CNN 比交叉测试-CNN 的PESQ、STOI、SDR 指标高0.227、0.150、4.877 dB。classify-DNN 比baseline-DNN 的PESQ、STOI、SDR指标提升0.278、0.160、0.500 dB,classify-CNN 比baseline-CNN 的PESQ、STOI、SDR 指标提升 0.074、0.054、2.003 dB。在基于matched、classify、交叉测试以及baseline 的语音分离方法中,本文提出的classify 方法性能与matched 方法接近,优于交叉测试和baseline 方法,不过整体语音分离性能比M-F组合略有下降。
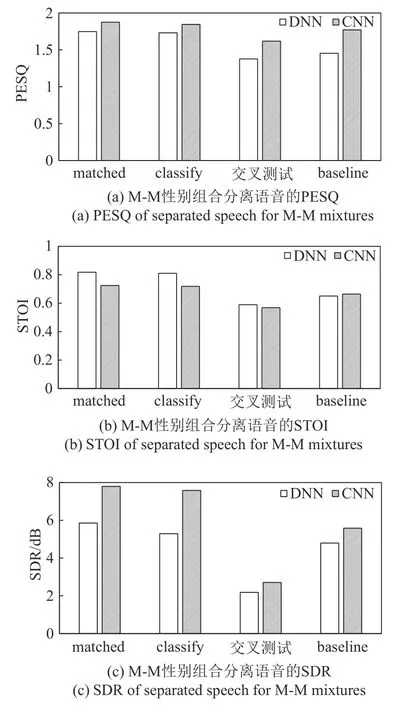
图10 M-M性别组合在DNN和CNN分离网络下的分离性能Fig.10 Performance of speech separation based on DNN/CNN M-M mixtures
4.2.3 女-女混合语音在不同分离模型下的分离性能比较
F-F性别组合混合语音的分离实验结果如图11所示。classify-DNN与matched-DNN的PESQ、STOI、SDR 指标上只相差0.115、0.015、0.126 dB,classify-CNN 与matched-CNN 的PESQ、STOI、SDR 指标上只相差0.053、0.010、0.282 dB。classify-DNN 比交叉测试-DNN 的PESQ、STOI、SDR 指标高0.213、0.144、2.719 dB,classify-CNN 比交叉测试-CNN 的PESQ、STOI、SDR 指标高0.235、0.168、3.707 dB。classify-DNN 比baseline-DNN 的PESQ、STOI、SDR 指标提升0.202、0.126、0.191 dB,classify-CNN 比baseline-CNN 的PESQ、STOI、SDR 指标提升0.148、0.053、1.661 dB。虽然F-F 性别组合的整体分离性能比起M-F 和M-M 要差,但仍然可以看出,本文提出的classify 方法优于交叉测试以及baseline 方法,与matched方法性能接近。
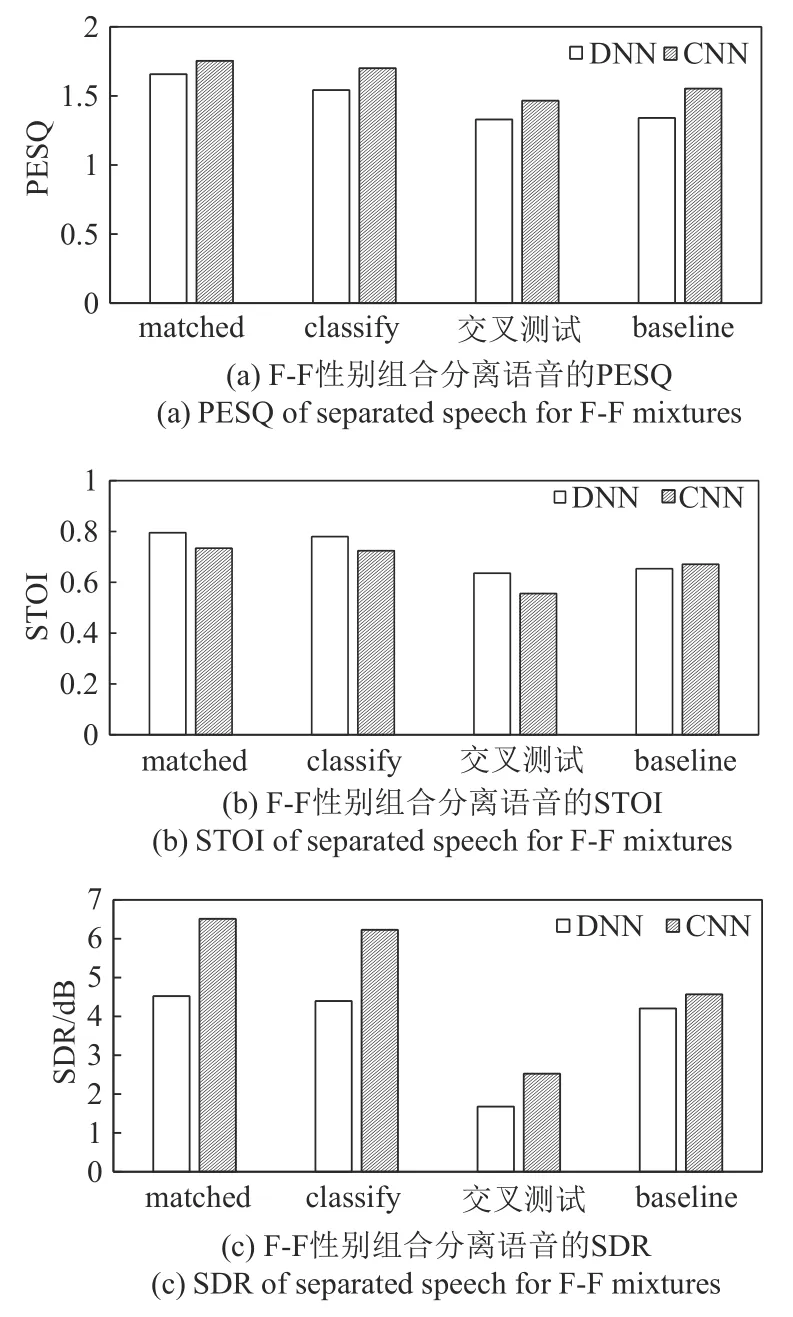
图11 F-F性别组合在DNN和CNN分离网络下的分离性能Fig.11 Performance of speech separation based on DNN/CNN for F-F mixtures
本文针对直接在普适分离模型上进行语音分离效果欠佳的问题,提出了一种 CNN-SVM 模型,对混合语音的性别组合进行判别,确定混合语音的两个说话人是男-男、男-女还是女-女组合,以便选用相应性别组合的模型进行语音分离。为了弥补传统单一特征在性别组合分类中区分力不足的缺陷,该模型提出了一种深度特征融合策略,使用卷积神经网络提取梅尔频率倒谱系数和滤波器组特征的深度特征,融合这两种深度特征作为最终的分类特征,通过深度挖掘使得分类特征中包含更多性别组合类别的信息。在未知混合语音性别组合的分类阶段,基于深度融合特征和SVM 分类器实现了高准确率判别混合语音性别组合;
在语音分离阶段,基于卷积神经网络和深度神经网络这两种模型进行了语音分离。三种性别组合下的语音分离实验表明:本文所提方法与性别组合完全匹配情况下的分离性能非常接近。比通用的分离网络性能有较大提升,远高于交叉测试的实验结果,验证了对混合语音性别组合先判断后针对每种性别组合训练一种分离网络的必要性以及本文分类方法的有效性。另外,为同性别混合信号设计更优秀的语音分离网络,使同性别组合的语音分离具有更好的性能,是下一步的研究方向。
扩展阅读文章
推荐阅读文章
老骥秘书网 https://www.round-online.com
Copyright © 2002-2018 . 老骥秘书网 版权所有